
I am a Senior Research Scientist at NVIDIA Spatial Intelligence Lab led by Prof. Sanja Fidler. I obtained my PhD from National University of Singapore, advised by Prof. Mike Shou and Prof. Wynne Hsu. My research interests include generative models for images, videos, 3D and 4D.
email: jay.zhangjie.wu [at] gmail.com
google scholar · github · linkedin · twitter
news
| Jun 2025 | Difix3D+ is recognized as the Best Paper Award Candidate at CVPR 2025. |
|---|---|
| Feb 2025 | We’re organizing WorldModelBench: The First Workshop on Benchmarking World Foundation Models at CVPR 2025. |
| Feb 2024 | Tutorial Diffusion-based Video Generative Models to appear at CVPR 2024. |
| Oct 2023 | Code and model weights of Show-1  are released! are released! |
| May 2023 | Organized LOVEU-TGVE (Text-Guided Video Editing) competition at CVPR 2023. |
| Apr 2023 | Searching for papers on video diffusion models? Check out our GitHub repo Awesome-Video-Diffusion  . . |
publications
(*) denotes equal contribution-
 ChronoEdit: Towards Temporal Reasoning for Image Editing and World SimulationICLR 2026 ·
ChronoEdit: Towards Temporal Reasoning for Image Editing and World SimulationICLR 2026 · -
-
 Difix3D+: Improving 3D Reconstructions with Single-Step Diffusion Models
Difix3D+: Improving 3D Reconstructions with Single-Step Diffusion Models -
 Cosmos-Drive-Dreams: Scalable Synthetic Driving Data Generation with World Foundation ModelsWhite Paper ·
Cosmos-Drive-Dreams: Scalable Synthetic Driving Data Generation with World Foundation ModelsWhite Paper · -
 Cosmos-Transfer1: Conditional World Generation with Adaptive Multimodal ControlWhite Paper ·
Cosmos-Transfer1: Conditional World Generation with Adaptive Multimodal ControlWhite Paper · -
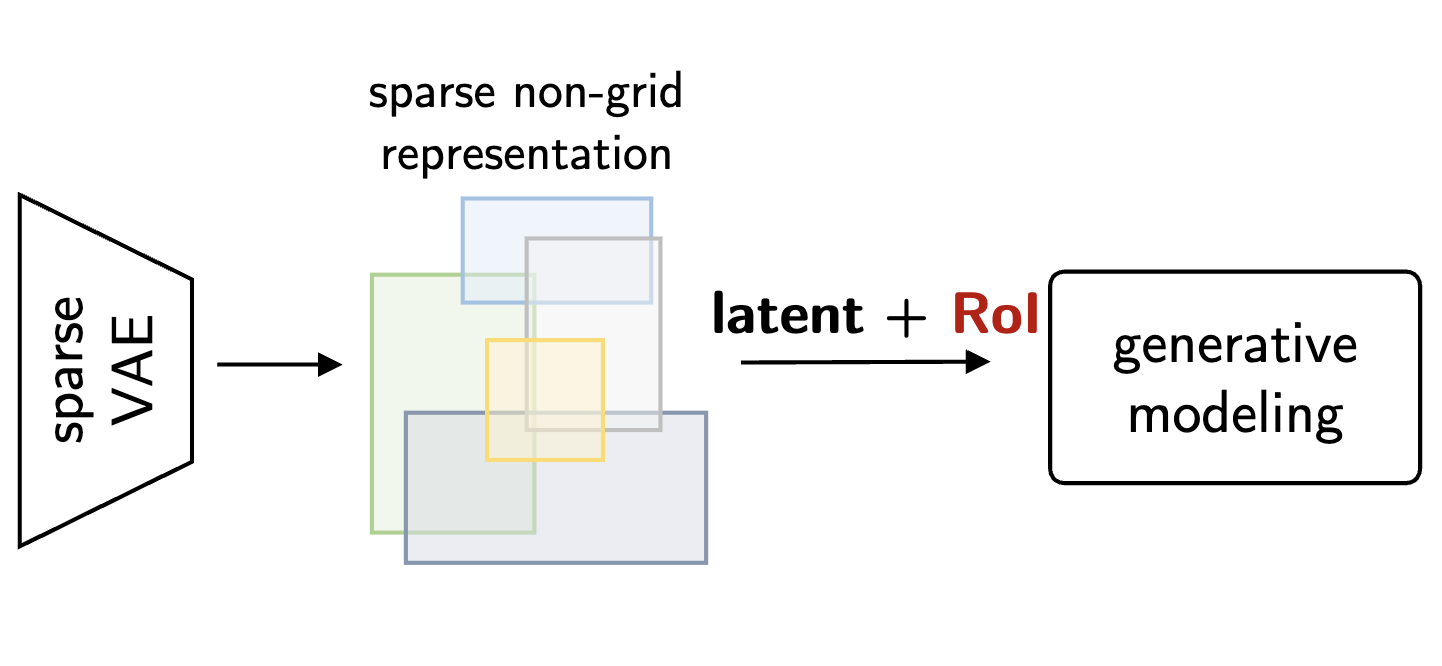
 Cosmos World Foundation Model Platform for Physical AI
Cosmos World Foundation Model Platform for Physical AI -
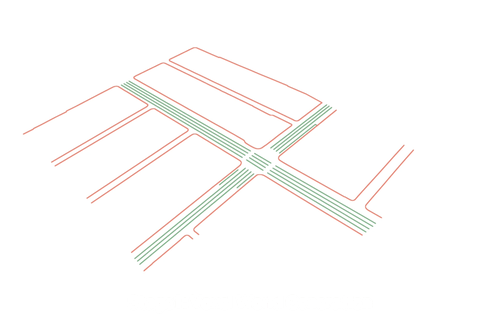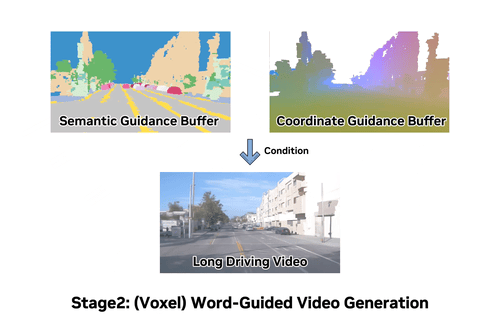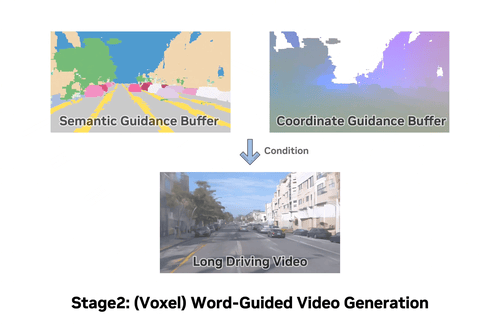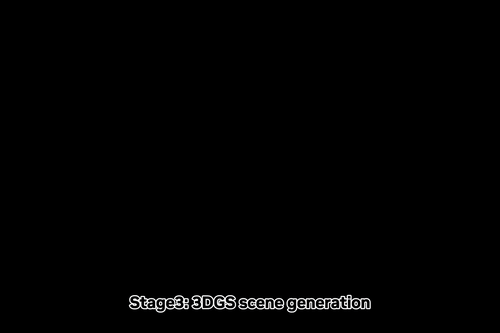 InfiniCube: Unbounded and Controllable Dynamic 3D Driving Scene Generation with World-Guided VideoICCV 2025 ·
InfiniCube: Unbounded and Controllable Dynamic 3D Driving Scene Generation with World-Guided VideoICCV 2025 · -
 SCube: Instant Large-Scale Scene Reconstruction using VoxSplatsNeurIPS 2024 ·
SCube: Instant Large-Scale Scene Reconstruction using VoxSplatsNeurIPS 2024 · -
 MotionDirector: Motion Customization of Text-to-Video Diffusion ModelsECCV 2024 (Oral) ·
MotionDirector: Motion Customization of Text-to-Video Diffusion ModelsECCV 2024 (Oral) · -
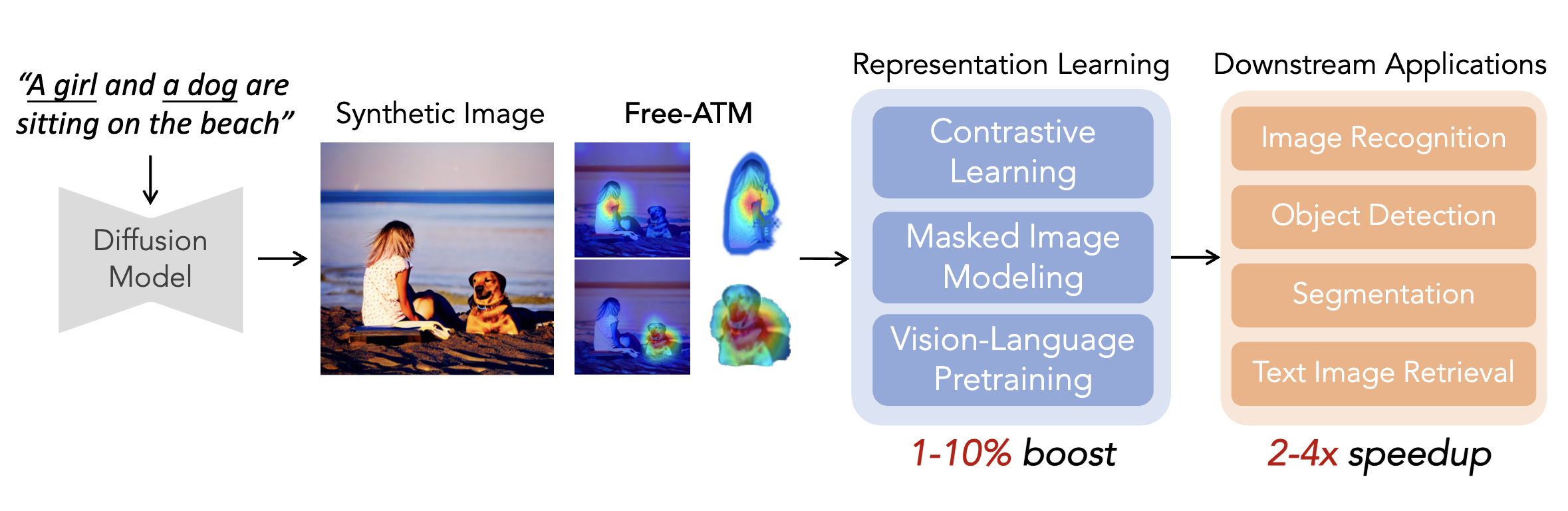 Free-ATM: Exploring Unsupervised Learning on Diffusion-Generated Images with Free Attention MasksECCV 2024
Free-ATM: Exploring Unsupervised Learning on Diffusion-Generated Images with Free Attention MasksECCV 2024 -
 VideoSwap: Customized Video Subject Swapping with Interactive Semantic Point CorrespondenceCVPR 2024 ·
VideoSwap: Customized Video Subject Swapping with Interactive Semantic Point CorrespondenceCVPR 2024 · -
 DynVideo-E: Harnessing Dynamic NeRF for Large-Scale Motion- and View-Change Human-Centric Video EditingCVPR 2024
DynVideo-E: Harnessing Dynamic NeRF for Large-Scale Motion- and View-Change Human-Centric Video EditingCVPR 2024 -
 Show-1: Marrying Pixel and Latent Diffusion Models for Text-to-Video GenerationIJCV 2024 ·
Show-1: Marrying Pixel and Latent Diffusion Models for Text-to-Video GenerationIJCV 2024 · -
 Mix-of-Show: Decentralized Low-Rank Adaptation for Multi-Concept Customization of Diffusion ModelsNeurIPS 2024 ·
Mix-of-Show: Decentralized Low-Rank Adaptation for Multi-Concept Customization of Diffusion ModelsNeurIPS 2024 · -
 Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation
Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation































